Nobel Prize in Physics 2024 — for Godfather’s of AI
The 2024 Nobel Prize in Physics was awarded jointly to John J. Hopfield and Geoffrey E. Hinton “for pioneering breakthroughs and innovations that have advanced the field of machine learning through artificial neural networks.”

John Joseph Hopfield was born on July 15, 1933, in Chicago, Illinois, USA. He is a theoretical physicist and biologist, and his work spans various scientific domains, from neurobiology to computational physics. Geoffrey Everest Hinton was born on December 6, 1947, in Wimbledon, London, England. He studied experimental psychology at Cambridge University before pursuing his Ph.D. in artificial intelligence from the University of Edinburgh in 1978.
Contribution from John Hopfield
Hopfield is best known for his work on Hopfield networks, which he introduced in 1982. A Hopfield network is a type of recurrent artificial neural network that can serve as an associative memory system. His contribution laid the groundwork for the concept of energy minimization in neural networks, which helped formalize how neural networks can solve complex optimization problems by iteratively converging on stable states (or “memories”). This approach inspired future work on understanding how biological systems process information and contributed directly to the evolution of artificial neural networks in AI.
Contribution from Geoffrey Everest Hinton
Hinton’s contributions are fundamental to the development of deep learning, a subset of machine learning that uses neural networks with many layers (deep neural networks). His work on backpropagation, a key algorithm for training neural networks by adjusting weights through error correction, was groundbreaking. Along with his collaborators, Hinton showed how neural networks could be effectively trained, even for complex tasks, by propagating errors back through the layers, allowing these networks to learn intricate patterns from large datasets.
Another of Hinton’s notable contributions is the concept of Boltzmann machines, a type of stochastic recurrent neural network that can represent complex distributions and perform probabilistic inference.
Artificial Intelligence / Machine Learning / Deep Learning

Machine Learning is a subset of artificial intelligence (AI) that involves the use of algorithms and statistical models to enable computers to improve their performance on a task through experience. ML models learn from data and make predictions or decisions without being explicitly programmed for the task.
Neural Networks: Composed of layers of interconnected nodes (neurons), where each layer extracts higher-level features from the data.
- Large Datasets: Requires large amounts of data for training to achieve high performance.
- High Computational Power: Typically requires powerful GPUs or specialized hardware for training.
Deep Learning is a subset of Neural Networks, a subset of machine learning involving neural networks with many layers (deep neural networks). It is particularly effective at learning from large amounts of unstructured data such as images, audio, and text.
Why is Neural Network Hot today?

Neural Networks have become a dominant force in modern artificial intelligence and machine learning because of three key factors: Big Data, advances in hardware (GPUs), and evolution in software and models (like the Perceptron, CNN, RNN, Transformers). Let’s break down why Neural Networks are “hot” today based on these elements:
1. Big Data: Fueling Neural Networks
- Availability of Data: Neural networks thrive on large amounts of data, which help the models learn complex patterns and improve their performance. The internet, smartphones, sensors, social media, e-commerce platforms, and other data sources have generated massive amounts of structured and unstructured data.
- Data Variety and Volume: Neural networks excel at tasks like image recognition, language translation, speech processing, and recommendation systems because modern applications provide huge datasets that include text, audio, video, and more. These data are essential for deep learning models, which require immense datasets to achieve high accuracy.
Why It Matters: In the past, machine learning models had limited access to large-scale data. Today, thanks to Big Data, neural networks can be trained on much richer and more diverse data, which is crucial for their success in real-world applications.
2. Hardware Advancements: Unleashing Neural Network Power
- GPUs and TPUs: The growth of specialized hardware like Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) has revolutionized the computational power needed for training neural networks. Unlike traditional CPUs, GPUs are highly parallelized, meaning they can process many computations simultaneously, which is ideal for neural network training that involves heavy matrix multiplication and other computationally expensive operations.
- Faster Training and Inference: Neural networks, especially deep learning models with millions or even billions of parameters (e.g., Transformer-based models like GPT), require vast computational resources. GPUs have enabled researchers and engineers to train these models faster than ever before, making the development cycle more efficient. This power makes it feasible to build sophisticated AI systems like self-driving cars, natural language processing (NLP) models, and real-time recommendation engines.
- Cloud Computing: Cloud platforms like AWS, Google Cloud, and Microsoft Azure offer on-demand access to powerful GPUs, allowing anyone to train large neural networks without the need for expensive in-house infrastructure. This democratization of resources has expanded the reach and development of neural networks across industries.
Why It Matters: In the past, training neural networks on large datasets took an unfeasible amount of time, but modern GPUs/TPUs now make this a matter of hours or days, greatly accelerating AI research and development.
3. Software and Model Innovations: Evolving Neural Network Architectures
- Perceptron: The Perceptron, invented by Frank Rosenblatt in 1958, was the earliest form of a neural network and inspired the fundamental building blocks of today’s deep learning. Although simple, it introduced the concept of learning weights from data, a core mechanism in modern neural networks.
- Convolutional Neural Networks (CNNs): CNNs, popularized by Yann LeCun, are a specialized kind of neural network for processing grid-like data, such as images. CNNs excel at recognizing visual patterns like edges, textures, and objects and are widely used in computer vision tasks like image classification, facial recognition, and autonomous driving.
- Recurrent Neural Networks (RNNs): RNNs, including Long Short-Term Memory (LSTM) networks, are designed for sequence data (e.g., time series, natural language) and are adept at capturing dependencies in sequential information. They have been instrumental in applications like speech recognition, language translation, and stock market prediction.
- Transformers: The introduction of Transformer models, like Google’s BERT and OpenAI’s GPT models, marked a revolution in natural language processing. Unlike RNNs, Transformers rely on attention mechanisms that allow them to focus on different parts of input sequences simultaneously. This has led to breakthroughs in language understanding, text generation, and translation, powering systems like ChatGPT and other large-scale language models.
Why It Matters: The evolution of neural network architectures, from basic Perceptrons to CNNs, RNNs, and Transformers, has unlocked new possibilities in AI. These sophisticated architectures enable machines to process complex, high-dimensional data and perform tasks that were once thought to be solely the domain of human intelligence.
Multi Layer Perceptrons and Back Propagation
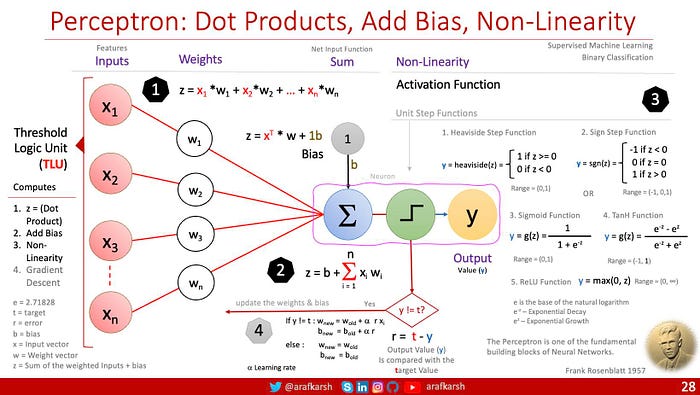
A Multi-Layer Perceptron (MLP) is a type of feedforward artificial neural network consisting of multiple layers of nodes (neurons). It is one of the simplest forms of neural networks that can solve complex problems, and is widely used in machine learning tasks.
MLP enables learning of complex, non-linear relationships through its multiple layers.
Backpropagation (short for “backward propagation of errors”) is the algorithm used to train neural networks, including MLPs. It calculates the error between the predicted output and the actual output, and then adjusts the weights of the network to minimize this error.
Backpropagation is critical for training deep networks efficiently by minimizing errors and enabling large-scale learning from data. Together, they form the foundation of most modern neural network-based models in AI.
Why Neural Networks Are Thriving Today
The convergence of Big Data, powerful hardware, and advanced models has created a fertile environment for neural networks to thrive. Here’s why they are particularly relevant:
- Data Availability: Neural networks need vast amounts of data to learn, and the explosion of Big Data has provided just that. Large datasets enhance the ability of models to generalize well to real-world scenarios.
- Hardware Efficiency: Modern hardware (GPUs/TPUs) allows for the efficient training of large and deep neural networks, turning once infeasible projects into reality. Real-time AI applications like self-driving cars and voice assistants are possible because of this.
- Software Evolution: The continuous development of neural network architectures like CNNs, RNNs, and Transformers has expanded the range of problems that AI can solve. From image recognition to natural language processing, neural networks now dominate key areas of AI.
In short, neural networks are hot today because the world is now equipped with the data, computational power, and advanced architectures to make them work efficiently at scale. These technologies power innovations in fields like healthcare (medical imaging), finance (fraud detection), entertainment (recommendation systems), and more, making them central to AI’s explosive growth.
What exactly is Machine Learning?
Here’s a comparison of two scenarios to illustrate the difference between a Rule Engine and a Machine Learning system. In the first scenario, “Making a cup of tea,” and in the second, “Learning to ride a bicycle,” we will determine which approach — Rule Engine or Machine Learning — is better suited for each task.
Use Case 1: How to make a cup of tea?

Use Case 2: How to ride a bicycle?

Analysing the Use Cases

Business Rule Engine:
- Predefined Rules/Instructions: Operates based on specific, clearly defined rules. As long as the rules and data remain unchanged, the output will always be consistent. However, it is unable to adapt to new business scenarios unless the rules are manually updated.
Machine Learning:
- Rules Derived from Training Data: The system learns and creates rules based on patterns identified in the training data. Each training process is unique, similar to how learning varies for different individuals, with the duration influenced by factors such as age or experience. Machine learning systems can adapt to new environments and evolving conditions without requiring manual rule adjustments.
Gen AI — The new Kid on the block
Generative AI refers to systems capable of generating new content, such as text, images, audio, and even code, based on input data. Instead of simply analyzing data, generative AI models create outputs like human-like text, realistic images, or deepfake videos. Examples include OpenAI’s GPT models (for text generation) and DALL·E (for image generation). Generative AI is used in chatbots, content creation, music generation, and more.

Foundation Models
Foundation Models are broad, versatile models trained on large-scale data that can be fine-tuned for a variety of downstream tasks. These models serve as a “base” for multiple applications and can be specialized for tasks like image recognition, NLP, or robotics. LLMs like GPT-3 are an example of foundation models in the language domain. They are powerful due to their general-purpose capability and can be customized for specific applications with minimal additional training.
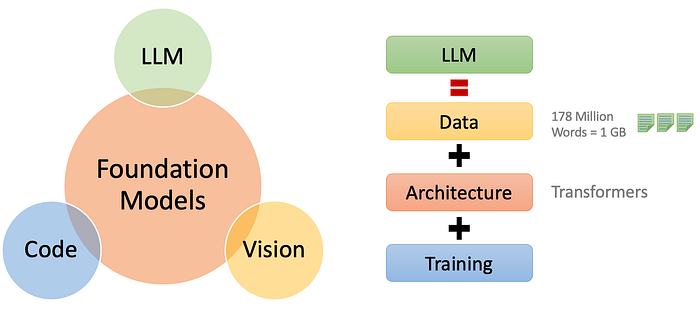
Large Language Models
LLMs are a subset of Foundation Models, trained on vast amounts of text data to understand and generate human language. These models have billions (or more) parameters and can perform tasks like translation, summarization, text completion, and question-answering. GPT-3, GPT-4, BERT, and Google’s PaLM are examples of LLMs. They use deep learning techniques, particularly transformer architectures, to handle complex linguistic tasks and context.
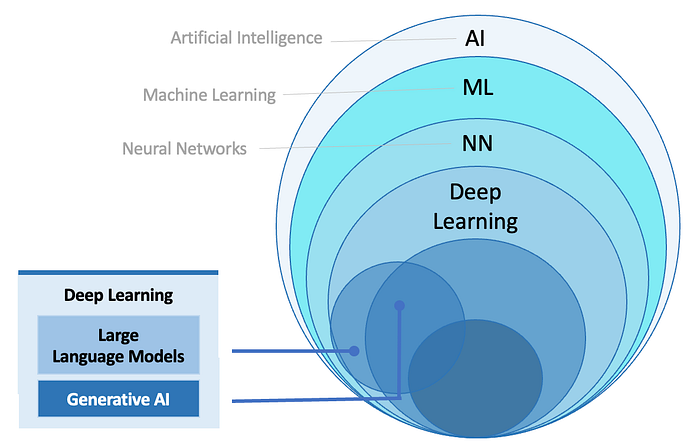
Thanks to the groundbreaking contributions of John Joseph Hopfield (Hopfield Networks, 1982) and Geoffrey Everest Hinton (Backpropagation, a key algorithm for training neural networks in 1986 & Deep Learning — CNN/RNN in 2012), the technological landscape is set to transform rapidly within our lifetime.
Stay tuned for more content on AI and Generative AI in the coming months, and in the meantime, feel free to explore the Machine Learning and Generative AI samples in my GitHub repository.
Gen AI Examples Java 21 and SpringBoot with LangChain: Java Examples using Deep Learning 4 Java & LangChain4J for Generative AI using ChatGPT LLM, RAG and other open source LLMs. Sentiment Analysis, Application Context-based ChatBots. Custom Data Handling. LLMs — GPT 3.5 / 4o, Gemini, Claude 3, Llama3, Phi-3, Gemma, Falcon 2, Mistral, Wizard Math: GitHub Repository
Further Research
- Nobel Prize: Nobel Prize for Physics 2024
- MathWorks: Convolutional Neural Networks
- MathWorks: Recurrent Neural Networks
- MathWorks: Introduction to Deep Learning
- MIT: Introduction to Deep Learning
- MIT: Recurrent Neural Network, Transformers & Attention
- MIT: Convolutional Neural Networks
- MIT: Deep Generative Modeling
- MIT: Reinforcement Learning
- MIT: Language Models & New Frontiers
- Stanford Lecture Series: Introduction to Convolutional Neural Networks
- YouTube: Understanding Back Propagation
- YouTube: Hopfield Network
- 3Blue1Brown: How Large Language Models Work.
- 3blue1Brown: Attention Transformers
- 3Blue1Brown: How might LLMs store facts

